

Produire du contenu avec l’intelligence artificielle est devenu simple. Le problème commence lorsque l’entreprise ne sait plus exactement quels textes ont été générés, quelles informations ont été vérifiées, quelles pages ont été validées et quels contenus peuvent engager son image ou sa responsabilité. Cet article répond à cette situation concrète : comment reprendre le contrôle sur des contenus produits ou assistés par IA déjà publiés, sans tout supprimer ni tout refaire.
L’audit devient alors une démarche de maîtrise éditoriale. Il permet d’identifier l’origine des contenus, de repérer les pages les plus sensibles, de vérifier les affirmations importantes, de corriger les passages fragiles et de conserver une trace claire des décisions prises. Cette logique devient d’autant plus utile que les obligations de transparence prévues par l’AI Act pour certains contenus générés par IA doivent entrer en application à partir du 2 août 2026. L’enjeu n’est donc pas de céder à l’urgence, mais de savoir quels contenus restent fiables, publiables et assumables.
Conseil pratique
Première action concrète pour tester la méthode sans déployer tout le dispositif.
- Exporter depuis le CMS un CSV listant URL, ID, auteur et date pour l’ensemble du périmètre visé.
- Ajouter une colonne « niveau de suspicion » et filtrer les pages les plus visibles (haut trafic ou pages commerciales) pour constituer le périmètre prioritaire.
- Appliquer la matrice simple visibilité × sensibilité pour marquer les items Haute et lancer un traitement sous 48-72 heures : vérification factuelle et capture de preuves.
- Renseigner les métadonnées minimales (origine_texte, résultat_verif, preuve_verif, statut_publication) pour les items traités et verrouiller les champs après validation.
Lancer l’export CSV et prioriser les 10 pages les plus visibles dès aujourd’hui
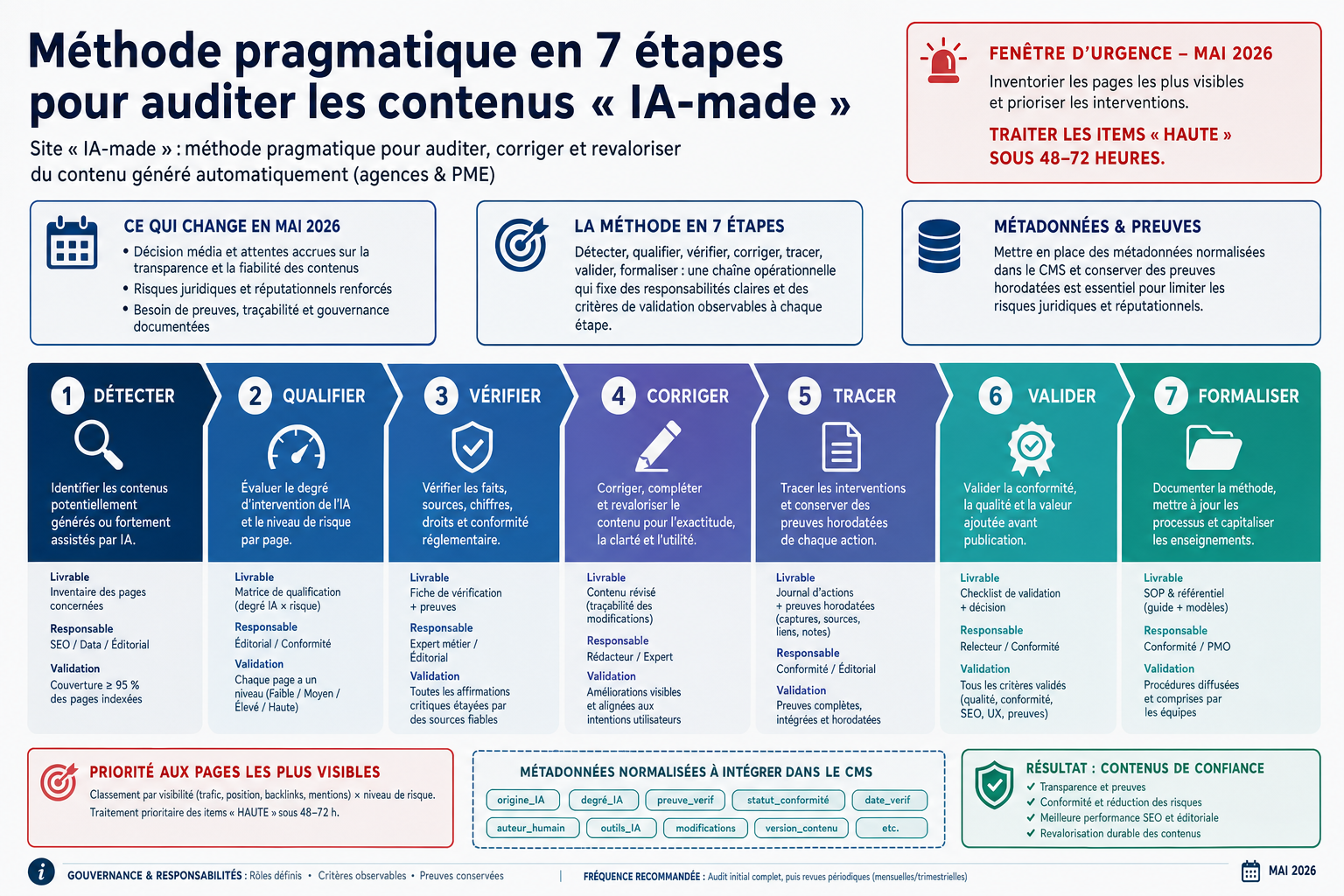
Méthode pragmatique en 7 étapes : passer du contenu incertain au contenu maîtrisé
La méthode repose sur sept étapes : détecter, qualifier, vérifier, corriger, tracer, valider et formaliser. Son objectif n’est pas simplement de repérer les contenus produits avec l’IA. Il s’agit surtout de savoir ce que l’entreprise peut encore publier en confiance, ce qui doit être corrigé, ce qui doit être documenté et ce qui demande une validation humaine ou client.
Cette approche permet de transformer un stock de contenus produits ou assistés par IA en patrimoine éditorial maîtrisé. Chaque étape répond à une question concrète : quels contenus sont concernés, lesquels sont prioritaires, quelles informations doivent être vérifiées, quelles corrections sont nécessaires, quelles preuves conserver, qui valide la version finale et comment éviter que le problème se reproduise à chaque nouvelle publication.
Il n’est pas nécessaire de tout auditer en une seule fois. L’approche la plus réaliste consiste à commencer par les contenus les plus visibles ou les plus sensibles : pages commerciales, articles à fort trafic, contenus contenant des chiffres, promesses de résultat, informations réglementaires, mentions de tiers ou éléments pouvant engager l’image de l’entreprise.
Étape 1 - Détection : savoir quels contenus sont concernés
Objectif : repérer les pages, articles, fiches produits, scripts, visuels ou contenus audio susceptibles d’avoir été produits, enrichis ou fortement réécrits avec l’aide de l’IA. Cette première étape ne sert pas encore à juger la qualité du contenu. Elle sert à sortir du flou et à construire une base de travail claire.
Dans un CMS comme WordPress, le point de départ peut être un export CSV listant les URL, les identifiants de contenus, les auteurs, les dates de publication, les catégories et les statuts. Lorsque c’est possible, cet export peut être complété par les métadonnées existantes, l’historique éditorial, les brouillons conservés ou les indications internes liées à l’usage de l’IA.
Responsable principal : administrateur CMS, auditeur contenu ou responsable éditorial. Livrable attendu : un inventaire exploitable dans un tableur, avec une colonne indiquant le niveau d’assistance IA estimé : faible, moyen, élevé ou inconnu. Critère de validation : le périmètre audité est clairement défini et les contenus actifs les plus importants sont bien présents dans l’inventaire.
Étape 2 - Qualification des risques : décider quoi traiter en priorité
Objectif : classer les contenus pour décider de l’ordre d’intervention. Tous les contenus assistés par IA ne présentent pas le même niveau d’exposition. Une page institutionnelle peu consultée, un article d’actualité, une fiche produit commerciale ou un contenu traitant d’un sujet réglementaire ne doivent pas être audités avec la même priorité.
La méthode consiste à enrichir l’inventaire avec plusieurs critères : visibilité SEO, trafic, nature du sujet, présence de promesses commerciales, données chiffrées, mentions de tiers, niveau de sensibilité et impact potentiel sur la confiance du lecteur. Un score simple peut ensuite être utilisé, par exemple en croisant la visibilité du contenu avec son niveau de sensibilité.
Responsable principal : chef de projet éditorial ou responsable marketing. Livrable attendu : une liste priorisée en trois niveaux, par exemple haute, moyenne et basse priorité. Critère de validation : les contenus les plus exposés disposent d’une décision claire pour la suite : vérifier, corriger, dépublier temporairement, conserver ou faire valider.
Étape 3 - Vérification factuelle et sourcing : contrôler ce qui peut être contesté
Objectif : contrôler les affirmations vérifiables et conserver une preuve du travail effectué. Cette étape concerne principalement les dates, chiffres, noms propres, citations, références réglementaires, données techniques, promesses de résultat et affirmations susceptibles d’être contestées.
La procédure consiste à passer le contenu au crible d’une checklist simple. Chaque affirmation importante doit être confirmée par une source fiable, reformulée si elle est trop fragile, ou supprimée si elle ne peut pas être justifiée. Les sources utilisées peuvent être indiquées dans une colonne dédiée, avec l’URL, la date de consultation et une note courte expliquant la décision prise.
Responsable principal : éditeur, journaliste, expert métier ou juriste selon la nature du contenu. Livrable attendu : un inventaire enrichi avec une colonne « preuve_verif », une colonne « décision » et un statut par contenu : validé, modifié, à compléter ou à retirer. Critère de validation : les affirmations sensibles disposent d’une source, d’une correction ou d’une justification documentée.
Étape 4 - Correction éditoriale : rendre le contenu clair, utile et assumable
Objectif : améliorer la clarté, la crédibilité, le ton de marque et la pertinence SEO du contenu. La correction ne consiste pas seulement à retirer les erreurs. Elle doit aussi redonner au texte une intention éditoriale claire : pourquoi ce contenu existe, à qui il s’adresse et quelle valeur il apporte.
La méthode consiste à produire un brief de réécriture indiquant le ton attendu, les mots-clés prioritaires, les passages à corriger, les sources à intégrer, les éléments à supprimer et l’angle éditorial à renforcer. Lorsque c’est possible, une comparaison avant/après permet de garder une trace des changements effectués.
Responsable principal : éditeur final, rédacteur senior ou responsable de marque. Livrable attendu : une version corrigée du contenu, accompagnée d’un historique ou d’un commentaire éditorial. Critère de validation : les erreurs identifiées ont été traitées, le texte est plus clair, l’angle est mieux défini et le contenu apporte au moins un élément distinctif : contexte, exemple, analyse, source ou retour d’expérience.
Étape 5 - Traçabilité et métadonnées : garder la preuve des décisions prises
Objectif : conserver une trace claire de l’origine du contenu, du niveau d’intervention de l’IA et des vérifications réalisées. Cette traçabilité permet de retrouver rapidement les informations importantes si le contenu doit être modifié, justifié ou transmis à un client.
Dans le CMS, il est possible d’ajouter des champs standards comme : origine_IA, degré_IA, date_source, opérateur_humain, preuve_verif, statut_conformité et date_validation. Ces champs n’ont pas besoin d’être visibles publiquement. Ils servent d’abord à organiser le suivi interne et à documenter le processus éditorial.
Responsable principal : administrateur CMS, chef de projet ou responsable qualité. Livrable attendu : des métadonnées renseignées pour les contenus audités. Critère de validation : chaque contenu traité dispose d’un statut clair et d’une trace minimale permettant de comprendre ce qui a été vérifié, modifié ou validé.
Étape 6 - Validation client : éviter les décisions implicites
Objectif : obtenir une validation claire lorsque les contenus audités concernent un client, une marque, une prestation commerciale ou un périmètre contractuel. Cette étape évite les incompréhensions entre l’agence, le client et les personnes chargées de publier les contenus.
Le processus peut rester simple : transmettre une synthèse des contenus vérifiés, indiquer les corrections majeures, signaler les risques traités et demander une acceptation écrite lorsque le contexte le justifie. Cette validation peut prendre la forme d’un e-mail, d’un commentaire dans un outil de gestion de projet ou d’une case de validation dans un espace client.
Responsable principal : chef de projet, responsable de compte ou personne en charge de la relation client. Livrable attendu : une preuve d’acceptation ou de validation liée au contenu audité. Critère de validation : les décisions importantes ne restent pas implicites et peuvent être retrouvées en cas de question ultérieure.
Étape 7 - Formalisation du processus : éviter de refaire les mêmes erreurs
Objectif : rendre la méthode réutilisable pour les futures publications. L’audit ne doit pas rester une action ponctuelle menée après coup. Il doit progressivement devenir une étape normale du workflow éditorial lorsqu’un contenu est produit, enrichi ou corrigé avec l’aide de l’IA.
La formalisation peut prendre la forme de procédures internes, de modèles d’audit, de checklists, de règles de validation et de courtes sessions de formation. L’objectif est que chaque intervenant sache quoi vérifier, quand demander une validation, comment renseigner les métadonnées et où conserver les preuves.
Responsables principaux : auditeur contenu, éditeur final, responsable qualité, chef de projet et, si nécessaire, juriste. Indicateurs à suivre : nombre de contenus audités, taux de contenus corrigés, temps moyen de traitement, part des contenus avec métadonnées complètes et nombre d’erreurs récurrentes identifiées. Critère de validation : une procédure écrite existe, elle est utilisée sur un premier cycle complet et les premiers indicateurs permettent déjà d’améliorer le processus.
Risques juridiques et réputationnels à traiter en priorité
L’audit doit d’abord cibler les contenus qui peuvent exposer l’entreprise ou fragiliser sa crédibilité. Les principaux points de vigilance concernent l’usage non autorisé d’éléments appartenant à des tiers, les erreurs factuelles sur des pages très consultées, les promesses commerciales difficiles à justifier, les ambiguïtés autour des droits de cession lorsque le contenu a été produit avec l’aide de l’IA, les obligations de transparence applicables à certains contenus générés, ainsi que les cas sensibles comme les voix ou images synthétiques pouvant être associées à une personne réelle.
Pour chaque contenu prioritaire, l’objectif est de qualifier précisément le risque : quelle information pose problème, pourquoi elle peut être contestée, quelle est la visibilité de la page et quelle conséquence cela peut avoir pour l’image de l’entreprise ou la relation client. Cette analyse permet ensuite de choisir une action adaptée : corriger le passage, ajouter une source, reformuler une promesse commerciale, dépublier temporairement le contenu, demander une validation client ou ajouter une mention de transparence lorsque le contexte le justifie.
Les contenus classés en priorité haute doivent faire l’objet d’un traitement documenté. Le rapport peut rester simple, mais il doit indiquer la nature du risque, les éléments vérifiés, les sources utilisées, la décision prise et la personne responsable de la validation. Le journal de modifications, les captures, les URL consultées et les dates de vérification ne remplacent pas un avis juridique, mais ils donnent une preuve de méthode et facilitent le suivi éditorial en cas de question ultérieure.
| Element | Synthese |
|---|---|
| Point 1 | La fenêtre d'urgence identifiée en mai 2026 impose d’inventorier les pages les plus visibles et de prioriser les interventions pour les items Haute sous 48-72 heures. |
| Point 2 | La méthode en 7 étapes (détecter, qualifier, vérifier, corriger, tracer, valider, formaliser) fixe des responsabilités claires et des critères de validation observables à chaque étape. |
| Point 3 | La mise en place de métadonnées normalisées dans le CMS (origine_IA, degré_IA, preuve_verif, statut_conformité, etc.) et la conservation de preuves horodatées sont essentielles pour limiter les risques juridiques et réputationnels. |
Checklist opérationnelle, métadonnées et modèle de suivi
Pour rendre l’audit exploitable, il faut éviter de rester dans une simple appréciation subjective du contenu. L’entreprise doit pouvoir retrouver rapidement l’origine d’un texte, son niveau d’assistance IA, les vérifications effectuées, les corrections apportées et la personne qui a validé la version finale. Cette traçabilité peut être mise en place progressivement, à partir d’un jeu minimal de métadonnées dans le CMS ou dans un tableau de suivi partagé.
Le premier niveau de suivi peut reposer sur les champs suivants :
- origine_texte : humain, IA, mixte ou inconnu ;
- outil_utilisé : nom de l’outil ou du modèle, lorsque l’information est connue ;
- degré_assistance_IA : faible, moyen, élevé ou non déterminé ;
- date_verification : date de la dernière vérification du contenu ;
- operateur_humain : personne responsable de la vérification ou de la correction ;
- resultat_verif : validé, modifié, à compléter ou retiré ;
- preuve_verif : URL, source, capture, note interne ou date de consultation ;
- statut_publication : brouillon, en correction, validé, publié ou à revoir.
Le rapport d’audit peut rester simple. Il doit surtout permettre de comprendre rapidement ce qui a été contrôlé et quelle décision a été prise. Une structure efficace peut contenir quatre parties : un résumé des principaux risques identifiés, un inventaire priorisé des contenus, une fiche de suivi par contenu sensible, puis une synthèse des décisions prises avec la date et le responsable de validation.
Dans un workflow WordPress ou CMS, le processus peut suivre une logique claire : extraction des contenus à auditer, qualification du niveau de risque, correction en brouillon ou en environnement de préproduction, ajout des preuves de vérification, validation interne ou client, puis publication ou republication du contenu corrigé. Lorsque l’entreprise travaille pour un client, une synthèse courte peut être transmise avant validation afin d’éviter les décisions implicites.
Une part de ce suivi peut être automatisée, notamment l’export des URL, la récupération de certaines données de trafic, l’ajout d’un statut d’audit ou l’assignation d’un contenu à un responsable. En revanche, les décisions importantes doivent rester lisibles et validées humainement : reformuler une promesse commerciale, supprimer une affirmation fragile, ajouter une mention de transparence ou republier une page sensible demande un arbitrage éditorial.
Les indicateurs à suivre doivent rester utiles : part des contenus audités, nombre de contenus corrigés, temps moyen de traitement, volume de pages encore à vérifier, erreurs récurrentes identifiées et part des contenus disposant d’une trace de validation. Ces données permettent de mesurer l’avancement de l’audit, mais aussi d’améliorer le processus de production pour les prochains contenus assistés par IA.
Comment documenter l’audit pour assurer la traçabilité ?
La traçabilité est ce qui transforme un audit ponctuel en méthode professionnelle. Sans documentation, l’entreprise peut corriger un contenu, mais elle aura du mal à expliquer plus tard ce qui a été vérifié, pourquoi une modification a été faite, quelle source a été utilisée et qui a validé la version finale. L’objectif n’est pas de produire une procédure lourde, mais de conserver une preuve claire du travail réalisé.
La bonne approche consiste à créer un registre d’audit. Ce registre peut prendre la forme d’un tableau partagé, d’un export CSV enrichi, d’un espace projet ou de champs personnalisés dans le CMS. Chaque ligne correspond à un contenu audité : une page, un article, une fiche produit, un script, une image, une voix synthétique ou tout autre actif éditorial concerné.
Pour chaque contenu, le registre doit permettre de retrouver quatre informations essentielles : l’identité du contenu, le niveau de risque, les preuves de vérification et la décision finale. Cette structure évite de se limiter à une impression subjective du type « contenu relu » ou « contenu corrigé ». Elle donne une trace exploitable, compréhensible par une équipe éditoriale, un client ou un responsable qualité.
Les informations minimales à conserver
Un registre de traçabilité peut rester simple. Il doit toutefois contenir suffisamment d’informations pour comprendre l’historique du contenu et les décisions prises pendant l’audit.
- id_audit : identifiant unique de la ligne d’audit ;
- url_contenu : adresse de la page ou de l’actif contrôlé ;
- type_contenu : article, page commerciale, fiche produit, script, image, audio ou autre ;
- origine_texte : humain, IA, mixte ou inconnu ;
- niveau_assistance_IA : faible, moyen, élevé ou non déterminé ;
- niveau_risque : faible, moyen ou élevé ;
- points_verifies : chiffres, dates, sources, promesses commerciales, mentions de tiers, droits, transparence ;
- preuve_verification : source utilisée, URL, capture, note interne ou date de consultation ;
- decision_audit : conserver, corriger, compléter, dépublier temporairement ou faire valider ;
- responsable_validation : personne ayant validé la décision ;
- date_validation : date de validation ou de dernière mise à jour ;
- statut_final : en attente, corrigé, validé, publié ou à revoir.
Conserver les preuves sans alourdir le processus
La preuve de vérification ne doit pas forcément être complexe. Pour un article, il peut s’agir d’une ou plusieurs sources consultées, d’une capture de la page avant correction, d’un commentaire éditorial, d’une note expliquant pourquoi une affirmation a été supprimée ou d’un lien vers une version corrigée. Le plus important est de pouvoir reconstituer la décision : quel problème a été identifié, quelle action a été menée et sur quelle base.
Dans un environnement WordPress, cette traçabilité peut être organisée de deux façons. La première consiste à tenir un tableau externe, plus facile à manipuler au début. La seconde consiste à ajouter progressivement des champs personnalisés dans le CMS pour relier directement les informations d’audit aux contenus concernés. Les deux approches peuvent coexister : le tableau sert au pilotage global, tandis que les champs CMS servent au suivi opérationnel de chaque contenu.
Documenter aussi les décisions éditoriales
La traçabilité ne concerne pas seulement les sources. Elle doit aussi documenter les arbitrages éditoriaux. Lorsqu’une promesse commerciale est reformulée, lorsqu’un chiffre est supprimé, lorsqu’une mention de transparence est ajoutée ou lorsqu’un contenu est laissé publié malgré un risque faible, la décision doit être expliquée brièvement. Cette note évite de refaire le même débat plusieurs semaines plus tard.
Une formulation simple suffit : « chiffre non confirmé, supprimé », « source officielle ajoutée », « promesse reformulée pour éviter une garantie implicite », « contenu validé après correction », ou « page à revoir lors du prochain cycle d’audit ». Ces commentaires courts donnent de la valeur au registre, car ils rendent les décisions lisibles pour les personnes qui n’ont pas participé à l’audit initial.
Créer un journal de modifications
Le journal de modifications permet de suivre l’évolution du contenu dans le temps. Il indique ce qui a changé, quand, pourquoi et par qui. Il peut être intégré au registre d’audit ou conservé dans un document séparé. L’objectif est de ne pas perdre l’historique des corrections, surtout pour les contenus sensibles ou les pages commerciales importantes.
Un journal efficace peut contenir la date de modification, le nom du responsable, la version concernée, le type de changement, la justification et le statut après correction. Cette logique aide l’entreprise à distinguer une simple retouche éditoriale d’une correction liée à un risque identifié.
Ce que la traçabilité apporte concrètement
Une bonne documentation ne garantit pas à elle seule la conformité juridique d’un contenu. En revanche, elle apporte une preuve de méthode. Elle montre que l’entreprise a identifié les contenus sensibles, vérifié les affirmations importantes, corrigé les passages fragiles et conservé une trace des décisions prises. C’est cette discipline qui permet de passer d’une production IA difficile à contrôler à un patrimoine éditorial suivi, corrigible et assumable dans le temps.
Conclusion : reprendre le contrôle avant de produire davantage
L’enjeu n’est pas de supprimer tous les contenus produits avec l’IA, ni de bloquer la production éditoriale. L’enjeu est de savoir quels contenus restent fiables, publiables et assumables. Une entreprise qui a utilisé l’IA pour produire plus vite doit maintenant être capable d’identifier les pages concernées, de vérifier les informations sensibles, de corriger les passages fragiles et de conserver une trace des décisions prises.
La première action consiste à lancer un inventaire ciblé sur les pages les plus visibles : contenus à fort trafic, pages commerciales, fiches produits, articles contenant des chiffres, promesses de résultat ou références réglementaires. La deuxième consiste à établir une priorisation simple pour distinguer les contenus à vérifier rapidement de ceux qui peuvent être traités dans un second temps. La troisième consiste à mettre en place des métadonnées minimales pour ne pas perdre l’historique des corrections et validations.
Cette démarche transforme l’audit en outil de pilotage éditorial. Elle aide l’entreprise à réduire les zones d’incertitude, à clarifier ses responsabilités, à renforcer la qualité de ses contenus et à mieux valoriser son patrimoine éditorial. L’IA permet de produire plus vite ; l’audit permet de savoir ce qui reste solide, utile et défendable dans le temps.
Points clés à retenir
- La fenêtre d'urgence identifiée en mai 2026 impose d’inventorier les pages les plus visibles et de prioriser les interventions pour les items Haute sous 48-72 heures.
- La méthode en 7 étapes (détecter, qualifier, vérifier, corriger, tracer, valider, formaliser) fixe des responsabilités claires et des critères de validation observables à chaque étape.
- La mise en place de métadonnées normalisées dans le CMS (origine_IA, degré_IA, preuve_verif, statut_conformité, etc.) et la conservation de preuves horodatées sont essentielles pour limiter les risques juridiques et réputationnels.
Foire Aux Questions
Quel périmètre prioriser pour l’audit initial ?
Priorisez les pages les plus visibles : pages à fort trafic, contenus factuels sensibles (actualité, santé, finances), claims publicitaires et contenus utilisant voix synthétique. Ces critères figurent explicitement dans la méthode fournie.
Quels champs métadonnées minimal faut‑il ajouter au CMS ?
Le brouillon propose un jeu minimal : origine_texte (human | IA | mixte), outil_utilisé, degré_automation, date_source, opérateur_humain, résultat_verif, preuve_verif, statut_publication. Renseignez et horodatez ces champs pour chaque item traité.
Quel délai appliquer pour les items classés Haute priorité ?
La méthode prescrit un traitement sous 48-72 heures pour les items Haute, incluant vérification factuelle, correction et production d’un rapport de remédiation avant toute republication.
Qui doit être impliqué dans le workflow d’audit ?
Les rôles mentionnés dans le texte : ingénieur CMS / auditeur contenu pour l’inventaire, chef de projet éditorial pour la priorisation, journaliste/éditeur pour la vérification factuelle, juriste pour les mentions contractuelles, administrateur CMS pour la traçabilité et le verrouillage des métadonnées.
Quelles preuves conserver pour limiter la responsabilité ?
Conservez captures d’écran, URLs et timestamps ; documentez chaque assertion vérifiée dans une colonne preuve_verif et liez les preuves au journal de modifications, comme indiqué dans la méthode.
Marques citées
WordPress
Site officielCMS open source de reference pour creer, gerer et faire evoluer des sites web.
Acteur majeur du web et de la recherche, souvent source des evolutions SEO et IA.
Sources et Références
- AI-generated actors and scripts are now ineligible for Oscars
- The best AI-powered dictation apps of 2025
- Artificial intelligence (AI) | European Commission
- Synthèse presse/veille - signaux 2026 sur IA générative et régulation
Pourquoi cet article
Pourquoi ce sujet maintenant - déclencheurs récents : 01net publie que près d’un tiers des nouveaux sites sont créés par l’IA, Google pousse à « penser pour les agents » et la visibilité organique évolue (Preferred Sources / signaux sémantiques). Ces signaux...



