
Déployer des LLM en local sur WordPress
Un basculement concret a eu lieu : depuis 2023‑2025 la mise à disposition de modèles open‑source (Llama 2, variantes 7B), la maturation d'outils d'inférence légers (llama.cpp, quantization GGML) et l'industrialisation des vecteurs sémantiques rendent viable l'exécution on‑premise ou sur serveurs privés pour enrichir des sites WordPress. Parallèlement, Google a précisé que le contenu généré par IA n'est pas automatiquement sanctionné mais que les systèmes favorisent le contenu utile et original, tandis que la CNIL et le cadre européen augmentent les obligations de conformité pour les traitements de données. Pour les agences digitales, l'enjeu immédiat est double : concevoir des architectures opérationnelles sûres et scalables, et formaliser des contrôles SEO et juridiques avant toute automatisation de production. Cet article propose un plan technique et une checklist pratique pour mettre en production des LLM locaux sans sacrifier référencement, sécurité ou conformité.
Conseil pratique
Un essai réaliste doit rester limité, reproductible et vérifiable. Voici 3 étapes actionnables pour obtenir un premier résultat sans engager l'ensemble du site.
- Préparer un environnement de test (instance WordPress en staging) et installer un plugin d'intégration simple qui peut appeler une API locale.
- Choisir un modèle léger cité (variante 7B) et un runtime CPU quantifié (ex. llama.cpp/GGML) pour exécuter l'inférence sur une machine de test ; connecter une petite vector DB self‑hosted (ex. Weaviate ou Milvus) avec un corpus restreint.
- Valider le flux : extraction → embeddings → retrieval → réponse. Marquer les pages générées en noindex, faire révision humaine sur échantillon et mesurer indicateurs SEO (impressions, CTR, positions) avant toute montée en charge.
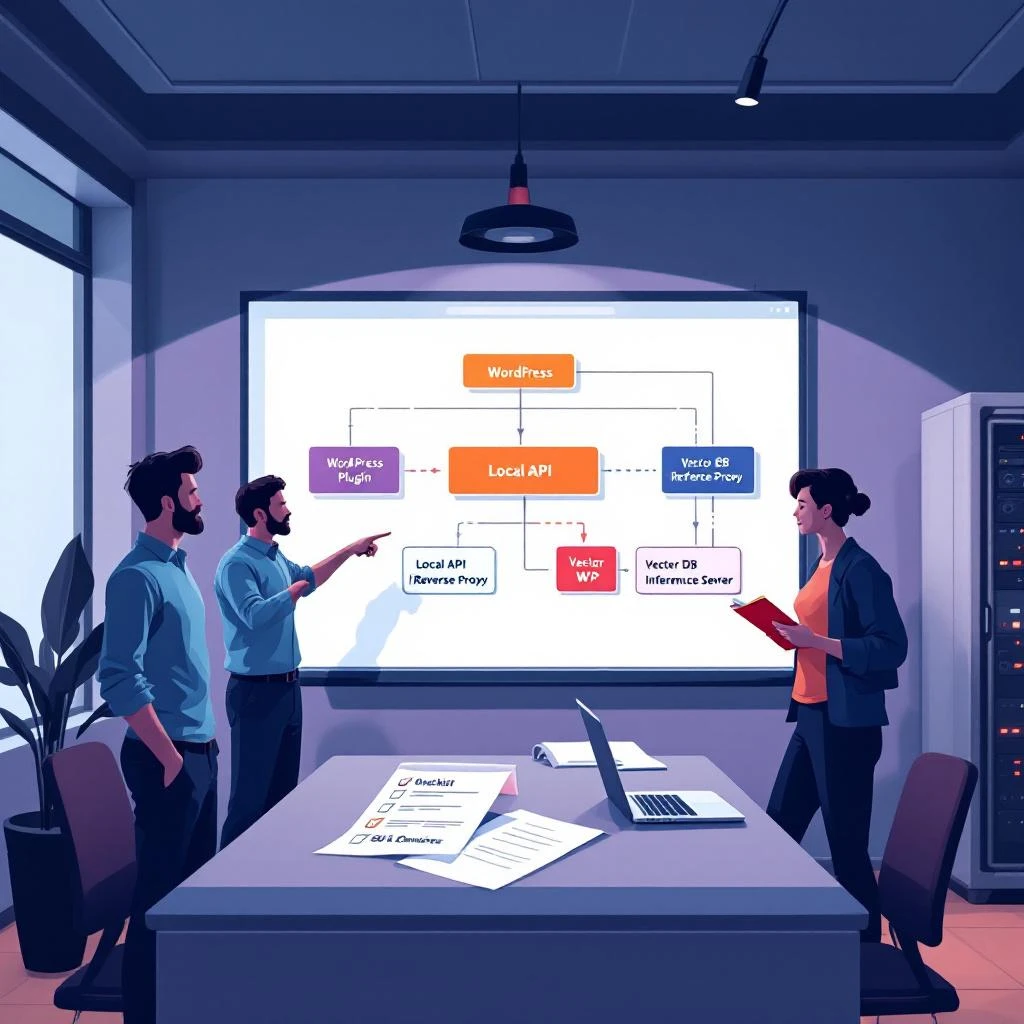
Architectures techniques et flux opérationnels
Composants essentiels et flux de données
Le schéma standard relie WordPress (front + REST API) à un plugin d'intégration qui orchestre les appels vers un reverse proxy ou une API locale d'inférence ; celle‑ci communique avec une base vectorielle pour retrieval et un service d'inférence (modèle quantifié ou serveur GPU) pour generation ou RAG. Le plugin gère l'extraction de texte, les webhooks d'indexation et le déclenchement des embeddings/retrieval. L'authentification se met en place via JWT ou OAuth, tandis que le système doit inclure caching des réponses côté edge et contrôle de charge (rate limiting, circuit breaker) pour préserver la stabilité du site.
Options modèles et stratégies d'inférence
Les familles de modèles se choisissent selon compromis matériel/qualité : les variantes ~7B demandent peu de GPU et conviennent pour des completions courtes et tâches à latence faible, alors que les modèles 30–70B offrent meilleure cohérence sur prompts complexes mais imposent coût matériel élevé. Les optimisations applicables sont la quantization (8/4‑bit, int8/int4), une distillation légère, et le recours à outils d'inférence adaptés : llama.cpp/ggml pour CPU quantifié, transformers + accelerate ou HF‑inference pour GPU, et des options de production comme Triton ou ONNX. Les critères de choix incluent la latence cible, le coût d'infrastructure, l'exigence de qualité et la complexité des prompts ; la stratégie peut combiner serveurs CPU pour tâches peu critiques et GPU pour charges complexes.
Stockage sémantique et pipeline d'embeddings
La vector DB (exemples d'usage : Milvus, Pinecone self‑hosted, Weaviate) assure le retrieval : le pipeline d'indexation extrait des embeddings lors de l'ingestion, effectue nettoyage, chunking et association de métadonnées (URL, auteur, date de mise à jour). La cohérence entre WordPress et l'index nécessite des webhooks pour mises à jour et une ré‑indexation incrémentale pour éviter dérives sémantiques entre contenu publié et indexé.
Déploiement, orchestration et résilience
Pour déployer on utilise des images Docker d'inférence et un orchestrateur Kubernetes pour la montée en charge ; des modèles peuvent tourner on‑prem, en colocated ou en hybride avec des nœuds edge pour réduire la latence. Le monitoring passe par métriques et logs structurés (ex. Prometheus) et des politiques d'autoscaling pour pods CPU/GPU. Un plan de fallback (mode dégradé : templates statiques, recours à API externe payante) assure continuité et contrôle des coûts en cas de pic ou d'incident.
Sécurité technique et protection des données
La sécurité impose chiffrement en transit et au repos, séparation réseau (VPC/private subnets), gestion stricte des clés et minimisation des données envoyées au modèle via prompt‑engineering pour anonymiser. Il faut journaux d'audit, politique de suppression/TTL des données sensibles et tests de vulnérabilité (incluant tentatives d'injection de prompt) avant mise en production.

Points clés à retenir
- La conjonction de modèles open‑source (ex. Llama 2, variantes 7B), d'outils d'inférence légers (llama.cpp, GGML) et de bases vectorielles rend techniquement viable l'exécution locale ou sur infrastructure privée pour enrichir WordPress.
- Une architecture opérationnelle typique relie WordPress (plugin ↔ reverse proxy/API d'inférence) à une vector DB pour retrieval et à un service d'inférence (CPU quantifié ou serveur GPU), avec enjeux de caching, authentification et résilience.
- Les principaux risques SEO sont la production de pages de faible valeur, la duplication et les erreurs factuelles ; mitigations recommandées : chaîne homme‑dans‑la‑boucle, marquage/noindex temporaire, A/B tests SEO et métriques dédiées avec playbook de rollback.
Impact SEO : risques, opportunités et règles pratiques
L'utilisation de LLM locaux ne change pas la règle fondamentale : les moteurs privilégient contenu utile, original et pensé pour les utilisateurs. Les risques concrets sont la production massive de pages de faible valeur, la duplication automatique ou auto‑plagiat et les erreurs factuelles qui dégradent l'expérience utilisateur, générant un retour négatif sur la visibilité. Les opportunités incluent la personnalisation sémantique (FAQ dynamiques, snippets conversationnels, enrichissement de contenu), une production automatique de balises structurées (schema.org) et un mapping d'intentions en temps réel pour orienter le contenu. Pour mitiger les risques, instituer une chaîne homme‑dans‑la‑boucle, intégrer signaux E‑E‑A‑T (sources citées, auteurs identifiables), marquer ou n'indexer temporairement les pages générées jusqu'à validation et déployer A/B tests SEO (suivi des impressions, CTR, positions) avant une mise à l'échelle. Opérationnellement, prévoir métriques dédiées (delta de trafic organique, taux de rebond, taux de correction humaine) et règles de rollback si la visibilité baisse.
Checklist opérationnelle pour agences : juridique, sécurité, qualité et mise en production
Licences et conformité modèle
Vérifier la licence du modèle (usage commercial, contraintes de distribution) et documenter la provenance des checkpoints et des weights. Formaliser dans les contrats client/fournisseur une clause sur la responsabilité du contenu généré et conserver preuve de conformité aux conditions d'utilisation des modèles.
Protection des données et obligations CNIL / DPIA
Réaliser une étude d'impact (DPIA) lorsqu'il y a traitement de données personnelles ; définir bases légales, durées de conservation, mesures techniques (chiffrement, anonymisation) et modalités d'information et de recours des personnes. Tenir un registre des traitements et prévoir audits réguliers pour démontrer conformité.
Gouvernance contenu & process éditorial
Mettre en place une chaîne de validation homme‑dans‑la‑boucle : prompts et templates validés, étapes claires (brouillon → révision → publication), seuils d'automatisation définis (ce qui peut être publié automatiquement ou non). Marquer explicitement les contenus générés et conserver un log d'édition pour la traçabilité et les revues.
Tests techniques et QA avant production
Avant mise en prod, exécuter tests de performance (p95 latency), tests de montée en charge, évaluations de cohérence pour détecter hallucinations, pentests incluant injection de prompt et tests de récupération (rollback). Définir SLO/SLA et seuils d'alerte opérationnels pour déclencher procédures d'urgence.
Contrôles SEO et monitoring post‑lancement
Déployer plans d'A/B tests SEO, conserver des pages en noindex jusqu'à validation, surveiller quotidiennement les SERP et piloter dashboards (impressions, positions, CTR). Mettre en place un playbook de rollback en cas de perte d'autorité et une routine d'échantillonnage éditorial avec revues mensuelles.
Opérations, runbook et formation client
Fournir un runbook couvrant déploiement, mises à jour des modèles, procédure incident, suppression de données à la demande et recovery. Former équipes éditoriales et clients aux limites des modèles, aux processus de validation et aux indicateurs d'alerte à suivre.
Conclusion
Pour une agence digitale, déployer des LLM en local sur WordPress est aujourd'hui pragmatique mais nécessite une approche intégrée : architectures robustes (plugin↔API↔vector DB↔inference), batteries de tests techniques et SEO rigoureux, et conformité juridique/documentaire. La trajectoire recommandée est incrémentale : pilote contrôlé, mesures d'impact SEO, validation de la gouvernance humaine, puis industrialisation par itérations. Priorités immédiates avant toute mise en production : audit des licences, DPIA et plan de tests SEO.
Sources : éléments et directives fournis dans le plan de référence de la mission (incluant mentions sur Llama 2, variantes 7B, llama.cpp, GGML, bases vectorielles, recommandations SEO et obligations CNIL).
Foire Aux Questions
Peut‑on héberger un LLM en local sans GPU ?
Le document mentionne que des variantes ~7B peuvent être utilisées avec des outils d'inférence légers (llama.cpp, GGML) pour CPU quantifié, mais précise que les modèles plus gros exigent du matériel plus coûteux et offrent de meilleurs résultats sur prompts complexes.
Quels sont les risques SEO concrets à anticiper ?
Les risques identifiés sont la production de pages de faible valeur, la duplication automatique et les erreurs factuelles menant à une mauvaise expérience utilisateur. Les mesures indiquées incluent chaîne homme‑dans‑la‑boucle, marquage/noindex temporaire, A/B tests SEO et métriques de suivi avec règles de rollback.
Quelles obligations juridiques faut‑il vérifier avant mise en production ?
Le brouillon recommande de vérifier les licences des modèles (usage commercial, distribution), de documenter la provenance des checkpoints et d'effectuer une DPIA lorsque des données personnelles sont traitées, avec registre des traitements et mesures techniques (chiffrement, anonymisation).
Comment assurer la sécurité des données envoyées au modèle ?
Mesures évoquées : chiffrement en transit et au repos, séparation réseau (VPC/subnets privés), gestion stricte des clés, minimisation des données dans les prompts, journaux d'audit et politiques de suppression/TTL.
Quels indicateurs suivre après le lancement d'un pilote SEO ?
Le texte recommande de suivre impressions, positions, CTR, delta de trafic organique, taux de rebond et taux de correction humaine, et de piloter des A/B tests SEO avec playbook de rollback si la visibilité diminue.
Marques citées
WordPress
Site officielCMS open source de reference pour creer, gerer et faire evoluer des sites web.
Acteur majeur du web et de la recherche, souvent source des evolutions SEO et IA.
Schema.org
Site officielStandard de donnees structurees utilise pour aider moteurs et IA a comprendre le contenu.
CNIL
Site officielAutorite francaise de reference pour la protection des donnees personnelles et la conformite.
Sources et Références
- REST API Handbook — WordPress Developer Resources
- Introducing Llama 2 (Meta AI announcement)
- Hugging Face — Running models locally & inference tools (docs and blog)
- llama.cpp (project) — lightweight C/C++ implementation for running Llama-style models
- Google Search Central — Helpful content and auto-generated content guidance
- Commission Nationale de l'Informatique et des Libertés (CNIL) — ressources et recommandations
- Brouillon de la mission : WordPress et LLM en local (plan de référence)
Pourquoi cet article
Question implicite : pour un site WordPress client, vaut‑il mieux intégrer l’inférence LLM en cloud (SaaS) ou déployer des modèles en local/edge — et comment le faire sans casser la performance, la sécurité ni le référencement ? Tension réelle : montée des LLM « en local » (privacy, souveraineté, coûts récurrents) vs la facilité et la puissance des API cloud. Les agences sont sollicitées pour livrer des fonctionnalités IA mais manquent de méthode pour arbitrer architecture, coûts, SLA et impacts SEO/ops. Pourquoi ce sujet mérite un article expert : Signal de fond : réveil des projets LLM en local (flux récents sur « LLM en local », régulation & souveraineté, inquiétudes sur l’exfiltration de données) ; traction chez les clients sensibles aux données (santé, assurance, collectivités). Enjeu concret : choisir une architecture (micro‑service d’inférence, vector DB, cache, worker d’embeddings, fallback SaaS) change coûts, latence, responsabilité juridique et classement SEO. Confusions fréquentes à corriger : que signifie « local » (edge, on‑prem, conteneur, inference on device) ; où stocker les embeddings ; comment préserver la rapidité de pages WordPress ; quelles données loguer/retention pour conformité. Angle éditorial proposé (suffisamment précis pour un article structuré et dense) : Corps principal : comparaison d’architectures (proxy SaaS, hybride SaaS+on‑prem, inference full on‑prem, inference edge), scénarios métiers (recherche sémantique, chat client, résumé d’articles, personnalisation) et tradeoffs (latence, coût total de possession, complexité ops, privacy). Conseil pratique : matrice décisionnelle pour choisir l’option selon profil client (trafic, sensibilité des données, budget, compétence ops). Démarrage rapide : recette pas‑à‑pas pour prototyper en 48h (stack recommandé : conteneur LLM léger ou quantifié, vector DB open source (Weaviate/Milvus), queue worker, plugin WP minimal, mise en cache et feature flag). Inclure commandes Docker, exemples d’API endpoints et checklist de tests de latence et sécurité. Points clés : dimensionnement CPU/GPU, stratégie d’update des modèles, coûts licencing, monitoring des dérives / hallucinations, rollback et plan de secours SaaS. Schéma pratique : diagramme d’architecture (WordPress → API Gateway → inference service local / vector DB → cache CDN / fallback SaaS), flux de données et zones sensibles à chiffrer. FAQ non artificielle : quand préférer SaaS ? Comment mesurer ROI d’un déploiement local ? Quel SLA proposer à un client ? Quels plugins WordPress éviter/valider ? Sources & encarts : benchmark public de modèles légers, liste d’outils open source recommandés, template d’encart commercial pour agences (offre packagée : audit, POC, exploitation). Valeur pour le lectorat NBComm : propose une traduction opérationnelle d’un signal faible mais structurant (LLM en local), corrige des confusions fréquentes, fournit des schémas et une checklist actionnable pour agences WordPress — donc immédiatement exploitable pour offres, audits techniques et choix stratégiques.








